|
Microsoft Excel��Microsoft��ʹ��Windows��Apple Macintosh����ϵ�y����X������һ����ӱ���ܛ����ֱ�^�Ľ��桢��ɫ��Ӌ�㹦�͈ܺD�����ߣ��ټ��ϳɹ����Ј��I�N��ʹExcel�ɞ������еĂ���Ӌ��C����̎��ܛ���� ���Ľ�BMicrosoft Excel��LINEST�������Z�����÷��� �����f��
LINEST��������Ҫ������ʹ����С���˷�����֪�����M�����ֱ���M�ϣ�������������ֱ���Ĕ��M�����˺������ؔ�ֵ���M�����Ա���Ԕ��M��ʽ����ʽݔ�롣 ֱ���Ĺ�ʽ�飺 y = mx + b or y = m1x1 + m2x2 + ... + b������ж����^��� x ֵ�� ʽ�У���׃�� y ����׃�� x �ĺ���ֵ��M ֵ���cÿ�� x ֵ��������ϵ����b �鳣����ע�� y��x �� m ������������LINEST �������صĔ��M�� {mn,mn-1,...,m1,b}��LINEST ����߀�ɷ��ظ��ӻؚw�yӋֵ�� �����Z��LINEST(known_y's,known_x's,const,stats)
LINEST(Y,X,߉ֵ,߉ֵ)
�����f��
Known_y's�����Pϵ���_ʽ y = mx + b ����֪�� y ֵ���ϡ� Known_x's�����Pϵ���_ʽ y = mx + b ����֪�Ŀ��x x ֵ���ϡ� -
���M known_x's ������һ�M���M׃�������ֻ�õ�һ��׃����ֻҪ known_y's �� known_x's �S����ͬ�������������κ��Π�ą^������õ�����׃�����t known_y's ��횞�����������횞�һ�л�һ�У��� -
���ʡ�� known_x's���t���Oԓ���M�� {1,2,3,...}�����С�c known_y's ��ͬ�� Const����һ߉ֵ������ָ���Ƿ��� b �����O�� 0�� Stats����һ߉ֵ��ָ���Ƿظ��ӻؚw�yӋֵ�� -
��� stats �� TRUE���t LINEST �������ظ��ӻؚw�yӋֵ���@�r���صĔ��M�� {mn,mn-1,...,m1,b;sen,sen-1,...,se1,seb;r2,sey;F,df;ssreg,ssresid}�� -
��� stats �� FALSE ��ʡ�ԣ�LINEST ����ֻ����ϵ�� m �ͳ��� b�� ���ӻؚw�yӋֵ���£� | �yӋֵ | �f�� | | se1,se2,...,sen | ϵ�� m1,m2,...,mn �Ę˜��`��ֵ�� | | seb | ���� b �Ę˜��`��ֵ���� const �� FALSE�r��seb = #N/A�� | | r2 | �ж�ϵ����Y �Ĺ�Ӌֵ�c���Hֵ֮�ȣ������� 0 �� 1 ֮�g������� 1���t�ӱ��кܺõ����P�ԣ�Y �Ĺ�Ӌֵ�c���Hֵ֮�g�]�в�e������ж�ϵ���� 0���t�ؚw��ʽ�����Á��A�y Y ֵ�����PӋ�� r2 �ķ�����Ԕ����Ϣ��Ո��醱����}����ġ��f������ | | sey | Y ��Ӌֵ�Ę˜��`� | | F | F �yӋ�� F �^��ֵ��ʹ�� F �yӋ�����Д���׃������׃��֮�g�Ƿ�ż���l���^���^�쵽���Pϵ�� | | df | ���ɶȡ������ڽyӋ���ϲ��� F �R��ֵ������õ�ֵ�� LINEST �������ص� F �yӋֵ�ı�ֵ���Á��Д�ģ�͵����Ŷȡ����P���Ӌ�� df��Ո����ڴ����}�к���ġ��f������ʾ�� 4 �f���� F �� df ��ʹ�á� | | ssreg | �ؚwƽ���͡� | | ssresid | ����ƽ���͡� ���PӋ�� ssreg �� ssresid �ķ�����Ԕ����Ϣ��Ո��醱����}����ġ��f������ | ����ĈDʾ�@ʾ�˸��ӻؚw�yӋֵ���ص���� 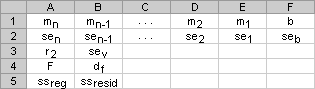
������ע -
����ʹ��б�ʺ� y �S�ؾ������κ�ֱ���� б�� (m)��
ͨ��ӛ�� m�������ҪӋ��б�ʣ��t�xȡֱ���ϵă��c��(x1,y1) �� (x2,y2)��б�ʵ��� (y2 - y1)/(x2 - x1)�� Y �S�ؾ� (b)��
ͨ��ӛ�� b��ֱ���� y �S�Ľؾ���ֱ��ͨ�^ y �S�r�c y �S���c�Ĕ�ֵ�� ֱ���Ĺ�ʽ�� y = mx + b�����֪���� m �� b ��ֵ���� y �� x ��ֵ���빫ʽ�Ϳ�Ӌ���ֱ���ϵ�����һ�c��߀����ʹ�� TREND ������ -
��ֻ��һ����׃�� x �r����ֱ���������湫ʽ�õ�б�ʺ� y �S�ؾ�ֵ�� б�ʣ�
=INDEX(LINEST(known_y's,known_x's),1) Y �S�ؾࣺ
=INDEX(LINEST(known_y's,known_x's),2) -
�������xɢ�̶țQ���� LINEST ����Ӌ��ľ��_�ȡ�����Խ�ӽ����ԣ�LINEST ģ�;�Խ���_��LINEST ����ʹ����С���˷����ж����m�ϔ�����ģ�͡���ֻ��һ����׃�� x �r��m �� b �Ǹ�������Ĺ�ʽӋ����ģ� 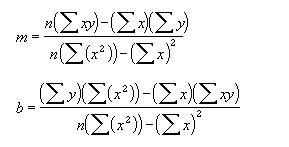
���� x �� y �ǘӱ�ƽ��ֵ������ x = AVERAGE(known x's) �� y = AVERAGE(known_y's)�� -
ֱ������������ LINEST �� LOGEST ���Á�Ӌ���c�o�������M�ϳ̶���ߵ�ֱ����ָ������������Ҫ�Д���������һ�����m�ϔ����������ú��� TREND(known_y's,known_x's) ��Ӌ��ֱ�������ú��� GROWTH(known_y's, known_x's) ��Ӌ��ָ���������@Щ�������� new_x's �ĺ������ڌ��H�����c�ϸ���ֱ�������������� y �Ĕ��Mֵ��Ȼ����Ԍ��A�yֵ�c���Hֵ�M�б��^��߀�����ÈD����ʽ��ֱ�^�ر��^���ߡ� -
�ؚw�����r��Microsoft Excel Ӌ��ÿһ�c�� y �Ĺ�Ӌֵ�͌��Hֵ��ƽ����@Щƽ����֮�ͷQ�隈��ƽ���� (ssresid)��Ȼ�� Microsoft Excel Ӌ�㿂ƽ���� (sstotal)���� const = TRUE �h���r����ƽ������ y �Č��Hֵ��ƽ��ֵ��ƽ����֮�͡��� const = FALSE �r����ƽ������ y �Č��Hֵ��ƽ���ͣ�����Ҫ��ÿ�� y ֵ�Мpȥƽ��ֵ�����ؚwƽ���� (ssreg) ��ͨ�^��ʽ ssreg = sstotal - ssresid Ӌ�����������ƽ�����c��ƽ���͵ı�ֵԽС���ж�ϵ�� r2 ��ֵ��Խ��r2 �DZ�ʾ�ؚw������ʽ�ĽY����ӳ׃���g�Pϵ�ij̶ȵĘ�־��r2 ���� ssreg/sstotal�� -
��ijЩ��r�£�һ������� X �п��ܛ]�г��F������ X ���е��A�yֵ�����O Y's �� X's λ�����У����Q��Ԓ�f���h��һ������� X �п��܌���ͬ�Ӿ��ȵ� y �A�yֵ�����@�N��r�£��@Щ����� X �Б�ԓ�Ļؚwģ���Єh�����@�N�F�Q�顰��������ԭ�����κζ���� X �б���ʾ������Ƕ��� X �еĺ͡�LINEST ���z���Ƿ���ڹ����������R�e����֮��Ļؚwģ���Єh���κζ���� X �С����ڰ��� 0 ϵ���Լ� 0 se's�������фh���� X ������ LINEST ݔ���б��R�e���������һ�������������б��h�����t��Ӱ� df��ԭ���� df ȡ�Q�ڱ����H�����A�yĿ�ĵ� X �еĂ��������PӋ�� df ��Ԕ����Ϣ��Ո��������ʾ�� 4��������ڄh������� X �ж������� df���tҲ��Ӱ� sey �� F ��ֵ�����H�ϣ�������ԓ�������ٰl�������ǣ��ܿ�����������r�ǣ���ijЩ X �ЃH���� 0's �� 1's ����һ������еČ����Ƿ����ij���M��ָʾ������� const = TRUE �h�����t LINEST ����Ч�ز������� 1's ������ X ���Ա�ģ�ͻ���ȡ�������һ�У�1 ������ÿ�����ԵČ���0 �����ڷ����Ԍ���߀��һ�У�1 ������ÿ��Ů�Ԍ���0 �����ڷ�Ů�Ԍ�����ô��һ�о��Ƕ���ģ�ԭ�������е�헿�ͨ�^������ 1's���� LINEST ���ӣ�����һ���Мpȥ������ָʾ�������е�헁��@�á� -
df ��Ӌ�㷽����������ʾ���]�� X �����ڹ�������ģ���б��h������������� known_x's �� k �к� const = TRUE �h������ô df = n �C k �C 1����� const = FALSE����ô df = n - k�����@�ɷN��r�£�ÿ�����ڹ������h��һ�� X �ж���ʹ df �� 1�� -
���ڷ��ؽY���锵�M�Ĺ�ʽ������Ԕ��M��ʽ����ʽݔ�롣 -
����Ҫݔ��һ�����M�������� known_x's�����酢���r���Զ�̖����ͬһ���Д����ķָ������Է�̖���鲻ͬ�Д����ķָ������ָ��������^���O�á��л�����塱�ġ��^���x헡��Ѕ^���O�õIJ�ͬ��������ͬ�� -
ע�⣬��� y �Ļؚw�����A�yֵ�������Á�Ӌ�㹫ʽ�� y ֵ�ķ��������������ǟoЧ�ġ�? ����ʾ��ʾ��1��б�ʺ� Y �S�ؾ� | ��֪ y | ��֪ x | | 1 | 0 | | 9 | 4 | | 5 | 2 | | 7 | 3 | | ��ʽ | ��ʽ | | =LINEST(A2:A5,B2:B5,,FALSE) |
| ע���ʾ���еĹ�ʽ����Ԕ��M��ʽݔ�롣�ڌ���ʽ���Ƶ�һ���հ��������x���Թ�ʽ��Ԫ���_ʼ�ą^�� A7:B7���� F2���ٰ� Ctrl+Shift+Enter�������ʽ�����Ԕ��M��ʽݔ�룬�t���؆��Y��ֵ 2�� ���Ԕ��Mݔ��r��������б�� 2 �� y �S�ؾ� 1�� ʾ��2�����ξ��Իؚw
| �� | �N�� | | 1 | 3100 | | 2 | 4500 | | 3 | 4400 | | 4 | 5400 | | 5 | 7500 | | 6 | 8100 | | ��ʽ | �f�����Y���� | | =SUM(LINEST(B2:B7, A2:A7)*{9,1}) | ����� 9 ���µ��N��ֵ (11000) | ͨ����SUM({m,b}*{x,1}) ���� mx + b�����o�� x ֵ�� y �Ĺ�Ӌֵ��Ҳ����ʹ�� TREND ������ ʾ��3�����ؾ��Իؚw ���O���_�l�����ڿ��]ُ�I�̘I�^���һ�MС���k���ǡ� �_�l�̿��Ը�������׃�������ö��ؾ��Իؚw�ķ���������o���^�ȵ��k���ǵărֵ�� ? | ׃�� | ���� | | y | �k���ǵ��u��ֵ | | x1 | ����e��ƽ��Ӣ�ߣ� | | x2 | �k���ҵĂ��� | | x3 | ��ڂ��� | | x4 | �k���ǵ�ʹ���ꔵ | ��ʾ�����O����׃����x1��x2��x3 �� x4������׃�� (y) ֮�g���ھ����Pϵ������ y ���k���ǵărֵ�� �_�l�̏� 1,500 �����x���k�������S�C�x���� 11 ���k��������ӱ����õ����Д��������낀��ڡ�ָ�����\ݔ������ڡ� | ����e (x1) | �k���ҵĂ��� (x2) | ��ڂ��� (x3) | �k���ǵ�ʹ���ꔵ (x4) | �k���ǵ��u��ֵ (y) | | 2310 | 2 | 2 | 20 | 142,000 | | 2333 | 2 | 2 | 12 | 144,000 | | 2356 | 3 | 1.5 | 33 | 151,000 | | 2379 | 3 | 2 | 43 | 150,000 | | 2402 | 2 | 3 | 53 | 139,000 | | 2425 | 4 | 2 | 23 | 169,000 | | 2448 | 2 | 1.5 | 99 | 126,000 | | 2471 | 2 | 2 | 34 | 142,900 | | 2494 | 3 | 3 | 23 | 163,000 | | 2517 | 4 | 4 | 55 | 169,000 | | 2540 | 2 | 3 | 22 | 149,000 | | ��ʽ |
|
|
|
| | =LINEST(E2:E12,A2:D12,TRUE,TRUE) |
|
|
|
| ע���ʾ���еĹ�ʽ����Ԕ��M��ʽݔ�롣�ڌ���ʽ���Ƶ�һ���հ��������x���Թ�ʽ��Ԫ���_ʼ�ą^�� A14:E18���� F2���ٰ� Ctrl+Shift+Enter�������ʽ�����Ԕ��M��ʽݔ�룬�t���؆��Y��ֵ -234.2371645�� �����锵�Mݔ��r������������Ļؚw�yӋֵ������ԓֵ���R�e����ĽyӋֵ�� 
���ػؚw��ʽ��y = m1*x1 + m2*x2 + m3*x3 + m4*x4 + b����ͨ�^�� 14 �е�ֵ�õ��� y = 27.64*x1 + 12,530*x2 + 2,553*x3 - 234.24*x4 + 52,318 �F�ڣ��_�l�������湫ʽ�ɵõ��k���ǵ��u���rֵ��������e�� 2,500 ƽ��Ӣ�ߡ�3 ���k���ҡ�2 ����ڣ���ʹ�� 25 �꣺ y = 27.64*2500 + 12530*3 + 2553*2 - 234.24*25 + 52318 = $158,261 ���ߣ��Ɍ��±���Ƶ�ʾ���������Ć�Ԫ�� A21�� | ����e (x1) | �k���ҵĂ��� (x2) | ��ڂ��� (x3) | �k���ǵ�ʹ���ꔵ (x4) | �k���ǵ��u��ֵ (y) | | 2500 | 3 | 2 | 25 | =D14*A22 + C14*B22 + B14*C22 + A14*D22 + E14 | Ҳ������ TREND ����Ӌ���ֵ�� ʾ��4��ʹ�� F �� R2 �yӋ �������У��ж�ϵ������ r2���� 0.99675������ LINEST ��ݔ����Ԫ�� A17 �е�ֵ������������׃���c�N�ۃr��֮�g���ںܴ�����P�ԡ�����ͨ�^ F �yӋ���_��������˸ߵ� r2 ֵ�ĽY��żȻ�l���Ŀ����ԡ� ���O������׃���g���������P�ԣ����x�� 11 ���k��������С�ӱ��M�нyӋ�����s���º������P�ԡ��g�Z��Alpha����ʾ�ó��@�ӵ����P�ԽYՓ�e�`�ĸ��ʡ� LINEST ݔ���е� F �� df �ɱ�����Ӌ��������F���^�� F ֵ�Ŀ����ԡ�F ���c�l���� F �ֲ����е�ֵ�M�б��^������ Excel �� FDIST �ɱ�����Ӌ��������F���^�� F ֵ�ĸ��ʡ������� F �ֲ����� v1 �� v2 ���ɶȡ���� n �ǔ����c�Ă������� const = TRUE �h������ô v1 = n �C df �C 1 �� v2 = df������� const = FALSE����ô v1 = n �C df �� v2 = df����Excel �� FDIST(F,v1,v2) ������������F���^�� F ֵ�ĸ��ʡ���ʾ�� 4 �У�df = 6 (cell B18) �� F = 459.753674 (cell A18)�� ���O���� Alpha ֵ���� 0.05��v1 = 11 �C 6 �C 1 = 4 �� v2 = 6����ô F ���R��ֵ�� 4.53����� F = 459.753674 �h���� 4.53������������F�� F ֵ�Ŀ����Էdz��͡������ Alpha = 0.05�����O�� F ���^�R��ֵ 4.53 �r���]�� known_y's �� known_x's ֮�g���Pϵ�ɱ��ܽ^��ʹ�� Excel �� FDIST �ɫ@��������F���^�� F ֵ�ĸ��ʡ�FDIST(459.753674, 4, 6) = 1.37E-7��һ���OС�ĸ��ʡ����ǿ��Ԕඨ���oՓͨ�^�ڱ��в��� F ���R��ֵ��߀��ʹ�� Excel �� FDIST���ؚw��ʽ���������A�yԓ�^���е��k���ǵ��u���rֵ��Ոע�⣬ʹ������һ����Ӌ����� v1 �� v2 �����_ֵ�Ƿdz��P�I�ġ� ʾ��5��Ӌ�� T �yӋ ��һ�����O�z���ԙz�ʾ���е�ÿ��б��ϵ���Ƿ�����Á�����ʾ�� 3 �е��k���ǵ��u���rֵ�����磬���Ҫ�z��ꔵϵ���ĽyӋ�@��ˮƽ���� 13.268����Ԫ�� A15 ����ꔵϵ���Ĺ���˜��`�ȥ�� -234.24���ꔵб��ϵ������������ T �^��ֵ�� t = m4 �� se4 = -234.24 �� 13.268 = -17.7 ��� t �Ľ^��ֵ������ô���Ԕඨ�Aбϵ�����Á�����ʾ�� 3 �е��k���ǵ��u���rֵ���±��@ʾ�� 4 �� t �^��ֵ�Ľ^��ֵ�� �����醽yӋ�փ���ı������l�F���pβ�����ɶȞ� 6��Alpha = 0.05 �� t �R��ֵ�� 2.447��ԓ�R��ֵ߀��ʹ�� Excel �� TINV ����Ӌ�㣬TINV(0.05,6) = 2.447����Ȼ t �Ľ^��ֵ�� 17.7������ 2.447���t�ꔵ���ڹ����k���ǵ��u���rֵ���f��һ���@��׃������ͬ�ӷ��������Ԝyԇ��׃���ĽyӋ�@��ˮƽ��������ÿ����׃���� t �^��ֵ�� | ׃�� | t �^��ֵ | | ����e | 5.1 | | �k���ҵĂ��� | 31.3 | | ��ڂ��� | 4.8 | | ʹ���ꔵ | 17.7 | �@Щֵ�Ľ^��ֵ������ 2.447����ˣ��ؚw��ʽ������׃�������Á�����^��ȵ��k���ǵ��u���rֵ��
Excel���w����څ��ƽ�滯���@�����º����������ĄӮ���ƽ�����^�ɣ�������ͬ������ʹ���w
|
